大模型的“幻觉”问题,是其行业落地的核心挑战之一。例如幻觉会影响生成内容的可靠性,对于法律、金融、医疗等专业要求高的领域,将难以完成实际场景任务。因此,大模型幻觉问题也被认为是制约大模型广泛应用的一大难题。近日,复旦大学与上海人工智能实验室构建了针对中文大模型的幻觉评测数据集HalluQA,对业界主流的大模型进行评估。
HalluQA采用无幻觉率来评估大模型的优劣。无幻觉率越高代表模型幻觉越低,事实准确性越高。评测的24个主流大模型中包括百度文心一言ERNIE-Bot、百川Baichuan、智谱ChatGLM、阿里通义千问和GPT-4等。
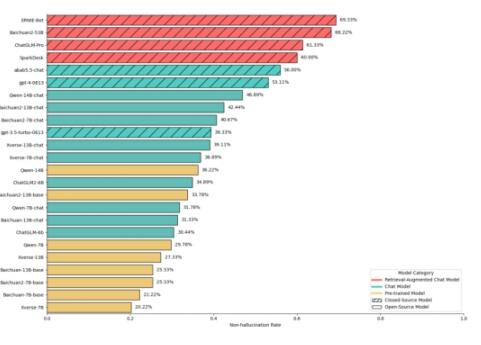
中文大模型幻觉评测数据集HalluQA对24个主流大模型进行评测
从评测结果来看,解决幻觉问题对大模型来说尚有困难,有18个模型的无幻觉率低于50%。在幻觉消除上,具备检索增强能力的大模型优势明显,在所有模型评测中,文心一言在整体幻觉问题解决方面表现突出,排名第一,整体无幻觉率为69.33%。而GPT-4整体无幻觉率为53.11%,排名第六。
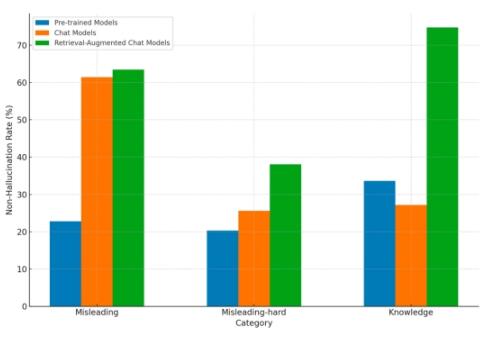
HalluQA:不同类型模型在不同类型的问题上的平均非幻觉率
行业普遍认为,幻觉问题对于大模型在多个领域的落地都可能产生严重影响,包括客户服务、金融服务、法律决策和医疗诊断等。因此解决幻觉问题越好的大模型,才具备更强的产业落地价值。





